UTF-8 字符串

Swift 5 将字符串的首选编码从 UTF-16 切换到 UTF-8,同时保留了高效的 Objective-C 互操作性。由于 String 类型抽象出了这些底层问题,因此开发者无需进行任何源代码更改*,但值得强调的是,此举现在和将来为我们带来的一些好处。
切换到 UTF-8 实现了 String 的长期目标之一,即实现高性能处理,这是性能敏感型开发者最强烈的要求。它还为将来提供更强大的性能 API 奠定了基础。String 的首选编码已嵌入到 Swift 的 ABI 中以提高性能,因此此切换必须在 Swift 5 中实现 ABI 稳定性。
* 有关潜在的行为更改(如果误用),请参见下文“慎用 String.Index.encodedOffset”
背景
结构的变化
即使 String 类型在技术上是一个结构体,但它可以以多种形式存在。您可以将 String 视为一种手工制作的枚举,它使用传统的 位操作 技术手工制作,以生成紧凑和高效的代码。
在 Swift 5 之前,字符串内容可以采用两种本机存储编码之一:用于 Unicode 富文本的 UTF-16,以及当内容全部为 ASCII 时使用的专用 ASCII 存储类。在 Swift 5 中,这两种编码被替换为单一的 UTF-8 存储编码,用于 ASCII 和 Unicode 富文本。
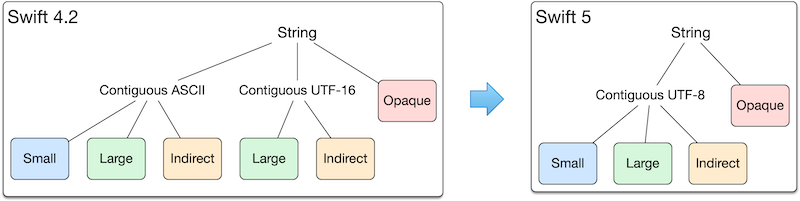
- 大型字符串由存储类支持,该存储类具有从对象地址固定偏移量处的尾部分配内容。
- 小型字符串将其内容直接打包在 String 结构体的位中,跳过任何分配。
- 间接字符串能够通过弹性函数调用提供指向连续内容的指针和长度。(弹性函数的行为可以修改,而不会破坏二进制兼容性。)
- 不透明字符串仅通过弹性函数调用实现功能,这意味着它们可以具有任何后备编码或表示形式。这意味着可以在任何时间点添加新的字符串形式。为了换取这种灵活性,它们无法从内联和其他优化中受益。
String 支持延迟桥接,这意味着将 NSString 导入 Swift 时不会复制它们。如果 NSString 能够提供指向连续内存中有效 UTF-8 的指针(例如,通过 CFStringGetCStringPtr),则将其作为间接字符串导入。否则,将其作为不透明字符串导入。
有关更多技术细节,请参见最近的 Swift 论坛帖子揭开字符串的面纱。
UTF-8:现代计算的正确选择
本机 UTF-8 支持对于与现代计算环境(包括以下环境)高效兼容至关重要:
- 服务器端和客户端编程
- 系统编程和 C 互操作性
- 开发者工具(构建系统、编辑器、linter 等)
例如,源代码(如大多数内容)以 UTF-8 编码,因此 SourceKit 将源代码中的位置表示和传达为 UTF-8 缓冲区中的偏移量。在 Swift 4.2 中,编写基于 UTF-8 服务的有效客户端需要维护从 UTF-8 偏移量到 UTF-16 索引的双向索引映射表。即使从 UTF-8 内容形成 Swift 4.2 字符串也涉及将内容转码为 UTF-16,这可能会非常耗费资源。例如,SwiftNIO 通过仅升级到 Swift 5,在提供 swift.org 首页时速度提高了 20%,这归功于跳过了此转码。
UTF-16 由 Unicode 早期版本设计的系统使用,当时所有标量都可以容纳在 16 位中。不幸的是,16 位最终变得过于限制,而 Unicode 现在使用 21 位标量。Swift 5 竭尽全力通过摊销的恒定时间 UTF-16 接口(请参阅下面的面包屑)提供与 Objective-C 和其他基于 UTF-16 的系统的高效互操作性。但是,UTF-8 是 Swift 5 中首选且最有效的表示形式。
编码差异
内存密度
对于字符串内容的任何 ASCII 部分,UTF-8 使用的内存比 UTF-16 少 50%。对于由后者BMP 标量组成的任何部分,UTF-8 使用的内存比 UTF-16 多 50%。对于来自拉丁/希腊语系或阿拉米语系的脚本以及任何非 BMP 标量(例如表情符号)的大多数非 ASCII 标量,两种编码的大小相等。
| AB | ГД | いろは | 𓀀𓂀 | |
|---|---|---|---|---|
| 标量 | U+0041 U+0042 |
U+0413 U+0414 |
U+3044 U+308D U+306F |
U+13000 U+13080 |
| UTF-8 | 41 42 |
D0 93 D0 94 |
E3 81 84 E3 82 8D E3 81 AF |
F0 93 80 80 F0 93 82 80 |
| UTF-16 | 41 00 42 00 |
13 04 14 04 |
44 30 8D 30 6F 30 |
0C D8 00 DC 0C D8 80 DC |
* UTF-16 是字节序相关的,此表列出了小端字节序中的字节
对性能敏感的字符串处理通常涉及处理大量包含 ASCII 的文本,这有利于 UTF-8。即使几乎完全由中文散文(后者 BMP 标量)组成的网站,由于 HTML 标记使用 ASCII,以 UTF-8 编码时也明显更小。与程序员可读字符串(如标识符、日志消息、URL、文本格式等)相比,用户可读的散文字符串仅占字符串使用量的一小部分。
Swift 4.2 的专用 ASCII 表示形式可以有效地编码全 ASCII 内容。但是,即使对于程序员可读的字符串,也越来越常见的是偶尔出现非 ASCII 内容,例如 Unicode 富标点符号。在 Swift 4.2 的字符串模型中,单个非 ASCII 标量会将整个内容强制转换为 UTF-16 存储。
解码和验证复杂性
UTF-8 和 UTF-16 都是可变宽度编码,但 UTF-16 的可变宽度最多为 2,而 UTF-8 的可变宽度最多为 4。这使得 UTF-16 对于非 ASCII 内容的解码和即时验证更加简单。但是,在现代处理器和 Swift 的性能模型下,这些优势被单一 UTF-8 存储表示形式的优势所掩盖(请参阅下面的统一存储表示形式)。
现代计算机系统具有向量扩展功能,并且可以乱序执行,这可以隐藏 UTF-8(相对而言)更复杂的解码过程的某些方面。在 UI 中显示用户可读文本需要比仅解码底层标量值更昂贵的计算,从而削弱了 UTF-16 的解码优势。对性能敏感的字符串处理算法通常在大量不透明字节中搜索特定的 ASCII 元字符序列。UTF-8 是此操作的理想表示形式。
Swift 5,与 Rust 一样,在创建时执行一次编码验证,此时执行验证效率更高。NSString 延迟桥接到 Swift 中并使用 UTF-16(零拷贝),可能包含无效内容(即隔离的代理项)。与 Swift 4.2 中一样,这些在读取时会延迟验证。
直接优势
由于此更改对 ABI 有重大影响,因此必须针对 Swift 5.0 版本进行此更改。虽然将 String 的编码切换为 UTF-8 的决定主要是出于超出版本范围的长期计划(从 SE-0247 开始),但即使在 Swift 5 中,此更改也带来了显著的好处。
C 互操作性
零终止 UTF-8 字符串与 C 字符串兼容,通过在我们的存储中维护零终止,本机字符串可以与 C 互操作而无需开销。诸如 myString.withCString { … } 之类的代码不再需要分配、转码并在稍后释放其内容,以便为闭包提供 C 兼容的字符串。相反,连续字符串只需提供其内部指针(小型字符串复制到临时堆栈空间中)。
延迟桥接的 NSString 仍然需要单独的分配/释放和转码。
统一存储表示形式
如上所述,Swift 5 从两种本机存储表示形式切换为一种。这允许进行更好的分析和更积极的优化,同时减少潜在的代码大小或编译时间成本。
例如,内联是一种编译器优化,可以提高运行时性能,但可能会增加代码大小。在 Swift 4.2 中,大多数字符串方法都包含一对实现,每种存储表示形式各一个。无论 4.2 字符串采用哪种形式,一部分可能内联的代码甚至都不会运行;这增加了成本并降低了内联的好处。此外,内联的最大好处来自特定于一个调用站点的后续分析和优化,这些分析和优化在双重表示形式上执行起来呈指数级困难。Swift 5 的统一存储表示形式更适合内联和后续优化。
这种统一的存储表示形式还促进了微小的调整和优化,这些调整和优化单独来看只能带来微小的收益,但结合起来可以成倍地提高性能。对 Swift 4.2 评估了每项优化,但由于模型复杂性,它们的优势有所降低,因为在双重存储表示形式上进行改造的成本更高。
Unicode 小型字符串
Swift 4.2 在 64 位平台上为长度最多为 15 个 ASCII 代码单元的字符串引入了小型字符串表示形式,而无需分配或内存管理。在 4.2 的模型中,这无法扩展到非 ASCII 内容,而无需添加另一种编码或小型字符串表示形式,如上所述,这会带来明显的缺点。
由于 Swift 5 切换到 UTF-8,小型字符串现在支持最多 15 个 UTF-8 代码单元的长度,而没有任何明显的缺点。这意味着您最重要的字符串(例如 "smol 🐶! 😍" )实际上可以是小型字符串。
这项新设计也使 32 位平台受益。虽然 Swift 4.2 没有小型字符串支持,但 Swift 5 在 32 位平台上支持最多 10 个 UTF-8 代码单元的小型字符串。
对现有代码的影响
我的代码应该更改什么?
对于大多数开发者来说,什么都不需要更改!
如果您发现自己出于性能原因而使用了 UTF16View,请重新评估您的基准测试,因为许多操作在 Swift 5 中更快。如果您仍然需要使用一些底层方法,则 UTF8View 是原生字符串的最佳性能视图。
对于性能敏感的代码,String.UTF8View 为原生字符串实现了 SE-0237,这意味着您可以通过调用 myString.utf8.withContiguousStorageIfAvailable { ... } 在内存中对连续的 UTF-8 字节执行闭包。SE-0247 基于此构建,并提供了更多便利。
使用 String.Index.encodedOffset 被认为是有害的 String.Index.encodedOffset 部分使用被认为是有害的永久链接" href="#use-of-stringindexencodedoffset-considered-harmful">
SE-0241 弃用了 String.Index.encodedOffset,因为它被广泛误用,这在 Swift 5 中更容易浮出水面。它提供了安全、更显式的索引映射替代方案。
Objective-C 互操作性
String 一直以来都为 Objective-C API 提供了高效的互操作性,Swift 5 仍然如此。String 的后备存储类是 NSString 的子类,因此它们可以免费桥接到 Objective-C。
借助新的 UTF-8 后备,String 在更多情况下通过 Objective-C API 直接访问其内容,从而在与桥接到 Objective-C 的 Swift 字符串交互时实现了 显著的加速。
切换到 UTF-8 编码内容给 Objective-C 互操作性带来了挑战,因为 Objective-C API 通常以 UTF-16 索引和长度表示。通常,将任意 UTF-8 索引转换为 UTF-16 索引将是线性时间扫描,但这对于桥接字符串来说将是不可接受的性能成本。为了解决这个问题,原生字符串(仅在请求时)通过利用面包屑策略,在 UTF-8 和 UTF-16 索引之间提供摊销的恒定时间互换。
面包屑
正如我们所见,将字符串的全部内容从 UTF-16 转码为 UTF-8 或反之亦然可能是一项代价高昂的操作。但是,将 UTF-16 偏移量转换为 UTF-8 偏移量是非常快速的线性扫描,本质上是对所有字节的高位进行求和。第一次在大型字符串上使用假设 O(1) 访问 UTF-16 的 API 时,它会执行此扫描并在固定步幅处留下面包屑,以便它可以以摊销的 O(1) 时间响应后续调用。
面包屑存储字符串索引数组和 UTF-16 代码单元中字符串的长度。ith 面包屑对应于 i * stride UTF-16 偏移量。将 UTF-16 偏移量映射到 UTF-8 偏移量以访问我们的内容从 breadcrumbs[offset / stride] 开始,并从那里向前扫描。从 UTF-8 偏移量映射到 UTF-16 偏移量(不太常见)从合理的估计开始,并从那里进行二分搜索,以找到后续扫描的上限和下限。
面包屑粒度为我们提供了一种在速度和大小之间取得平衡的方法。计算面包屑、它们的粒度,甚至它们的表示都隐藏在弹性函数调用之后,因此所有这些都可以在将来进行调整和修改。
目前,字符串使用非常精细的粒度,强烈倾向于速度,目的是不在任何实际情况下引入意外的回归。由在其上调用这些 API 的后者-BMP 标量组成的字符串在系统整体上具有非常低的内存占用,因此内存压力不是常见的担忧。随着这种扫描性能的提高,可以增加粒度而不会损害速度。
ASCII 是 UTF-16 的编码子集,这意味着如果字符串完全是 ASCII,则 UTF-8 偏移量与 UTF-16 偏移量相同。全 ASCII 字符串跳过面包屑并直接返回答案。
代码中的性能
任何重大的模型更改都存在在某些情况下性能回归的风险。如果您遇到任何问题,或者您有一些性能敏感的代码应该更快,请提交错误报告。String 将在每个版本中不断提供性能改进,用户的报告有助于识别和优先处理这些改进。