Swift 3 中的全模块优化

全模块优化是 Swift 编译器的一种优化模式。全模块优化的性能提升在很大程度上取决于项目,但可能高达两倍甚至五倍。
可以使用编译器标志 -whole-module-optimization (或 -wmo) 启用全模块优化,并且在 Xcode 8 中,对于新项目,默认情况下已启用它。此外,Swift Package Manager 在发布版本中会使用全模块优化进行编译。
那么这是关于什么的呢?让我们首先看看编译器在没有全模块优化的情况下是如何工作的。
模块以及如何编译它们
模块是一组 Swift 文件。每个模块都编译成一个单独的分发单元——框架或可执行文件。在单文件编译(不使用 -wmo)中,Swift 编译器会为模块中的每个文件单独调用。实际上,这就是幕后发生的事情。作为用户,您不必手动执行此操作。它由编译器驱动程序或 Xcode 构建系统自动完成。
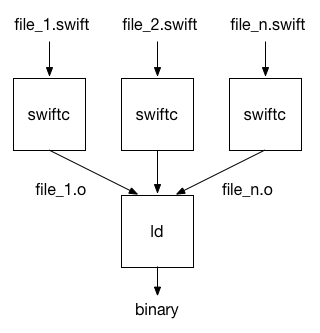
在读取和解析源文件(并执行一些其他操作,例如类型检查)之后,编译器优化 Swift 代码,生成机器代码并写入目标文件。最后,链接器组合所有目标文件并生成共享库或可执行文件。
在单文件编译中,编译器优化的范围仅限于单个文件。这限制了跨函数优化,例如函数内联或泛型特化,仅限于在同一文件中调用和定义的函数。
让我们看一个例子。假设我们模块的一个文件名为 utils.swift,其中包含一个泛型实用程序数据结构 Container<T>,其中有一个方法 getElement,并且该方法在整个模块中被调用,例如在 main.swift 中。
main.swift
func add (c1: Container<Int>, c2: Container<Int>) -> Int {
return c1.getElement() + c2.getElement()
}
utils.swift
struct Container<T> {
var element: T
func getElement() -> T {
return element
}
}
当编译器优化 main.swift 时,它不知道 getElement 是如何实现的。它只知道它存在。因此,编译器会生成对 getElement 的调用。另一方面,当编译器优化 utils.swift 时,它不知道该函数被调用的具体类型。因此,它只能生成该函数的泛型版本,这比针对具体类型特化的代码慢得多。
即使是 getElement 中简单的 return 语句也需要在类型的元数据中查找,以确定如何复制元素。它可以是一个简单的 Int,但也可能是一个更大的类型,甚至涉及一些引用计数操作。编译器只是不知道。
全模块优化
通过全模块优化,编译器可以做得更好。当使用 -wmo 选项进行编译时,编译器会将模块的所有文件作为一个整体进行优化。
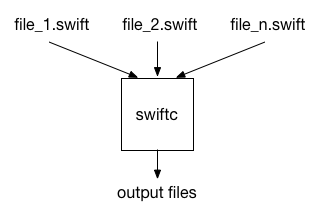
这有两个很大的优势。首先,编译器可以看到模块中所有函数的实现,因此它可以执行诸如函数内联和函数特化之类的优化。函数特化意味着编译器会创建一个新版本的函数,该函数针对特定的调用上下文进行了优化。例如,编译器可以为具体类型特化泛型函数。
在我们的示例中,编译器生成了泛型 Container 的一个版本,该版本针对具体类型 Int 进行了特化。
struct Container {
var element: Int
func getElement() -> Int {
return element
}
}
然后,编译器可以将特化的 getElement 函数内联到 add 函数中。
func add (c1: Container<Int>, c2: Container<Int>) -> Int {
return c1.element + c2.element
}
这编译成几条机器指令。与单文件代码相比,这是一个很大的不同,在单文件代码中,我们对泛型 getElement 函数进行了两次调用。
跨文件的函数特化和内联只是编译器能够通过全模块优化执行的优化示例。即使编译器决定不内联函数,如果编译器能够看到函数的实现,也会有很大帮助。例如,它可以推理其关于引用计数操作的行为。有了这些知识,编译器就能够删除函数调用周围冗余的引用计数操作。
全模块优化的第二个重要好处是编译器可以推理非公共函数的所有用法。非公共函数只能在模块内使用,因此编译器可以确保看到对此类函数的所有引用。编译器可以使用此信息做什么呢?
一个非常基本的优化是消除所谓的“死”函数和方法。这些是永远不会被调用或以其他方式使用的函数和方法。通过全模块优化,编译器知道是否完全没有使用非公共函数或方法,如果是这种情况,它可以消除它。那么,程序员为什么要编写一个根本不使用的函数呢?嗯,这不是消除死函数的最重要用例。通常,函数会作为其他优化的副作用而变成死函数。
假设 add 函数是调用 Container.getElement 的唯一位置。在内联 getElement 之后,不再使用此函数,因此可以将其删除。即使编译器决定不内联 getElement,编译器也可以删除 getElement 的原始泛型版本,因为 add 函数仅调用特化版本。
编译时间
使用单文件编译,编译器驱动程序为每个文件在单独的进程中启动编译,这可以并行完成。此外,自上次编译以来未修改的文件不需要重新编译(假设所有依赖项也未修改)。这称为增量编译。所有这些都节省了大量的编译时间,特别是当您只进行少量更改时。这在全模块编译中是如何工作的呢?让我们更详细地了解编译器在全模块优化模式下的工作方式。
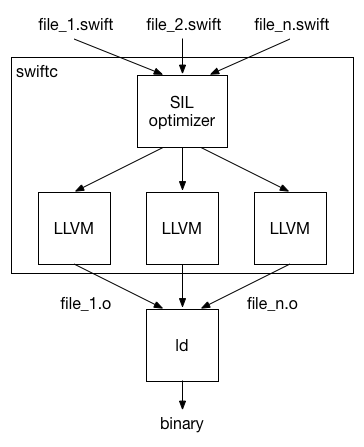
在内部,编译器在多个阶段运行:解析器、类型检查、SIL 优化、LLVM 后端。
在大多数情况下,解析和类型检查非常快,我们预计在后续的 Swift 版本中它会变得更快。“SIL 优化器”(SIL 代表“Swift 中间语言”)执行所有重要的 Swift 特有的优化,例如泛型特化、函数内联等。编译器的这个阶段通常占用大约三分之一的编译时间。大部分编译时间由 LLVM 后端消耗,后者运行较低级别的优化并执行代码生成。
在 SIL 优化器中执行全模块优化后,模块再次拆分为多个部分。LLVM 后端在多个线程中处理拆分的部分。如果某个部分自上次构建以来没有更改,它还会避免重新处理该部分。因此,即使使用全模块优化,编译器也能够并行(多线程)和增量地执行大部分编译工作。
结论
全模块优化是获得最大性能的好方法,而无需担心如何在模块中的文件中分发 Swift 代码。如果上述优化在关键代码段中生效,则性能可能比单文件编译高出五倍。并且您可以通过比典型的单片全程序优化方法更好的编译时间来获得这种高性能。